Upsertion
Upsert refers to the process of uploading and processing documents into vector stores, forming the foundation of Retrieval Augmented Generation (RAG) systems.
There are two fundamental ways to upsert data into vector store:
- Document Stores (Recommended)
- Chatflow Upsert
We highly recommend using Document Stores as it provides a unified interface to help with the RAG pipelines - retrieveing data from different sources, chunking strategy, upserting to vector database, syncing with updated data.
In this guide, we are going to cover another method - Chatflow Upsert. This is an older method prior to Document Stores.
For details, see the Vector Upsert Endpoint API Reference.
Understanding the upserting process
Chatflow allows you to create a flow that can do both upserting and RAG querying process, both can be run idenpendently.
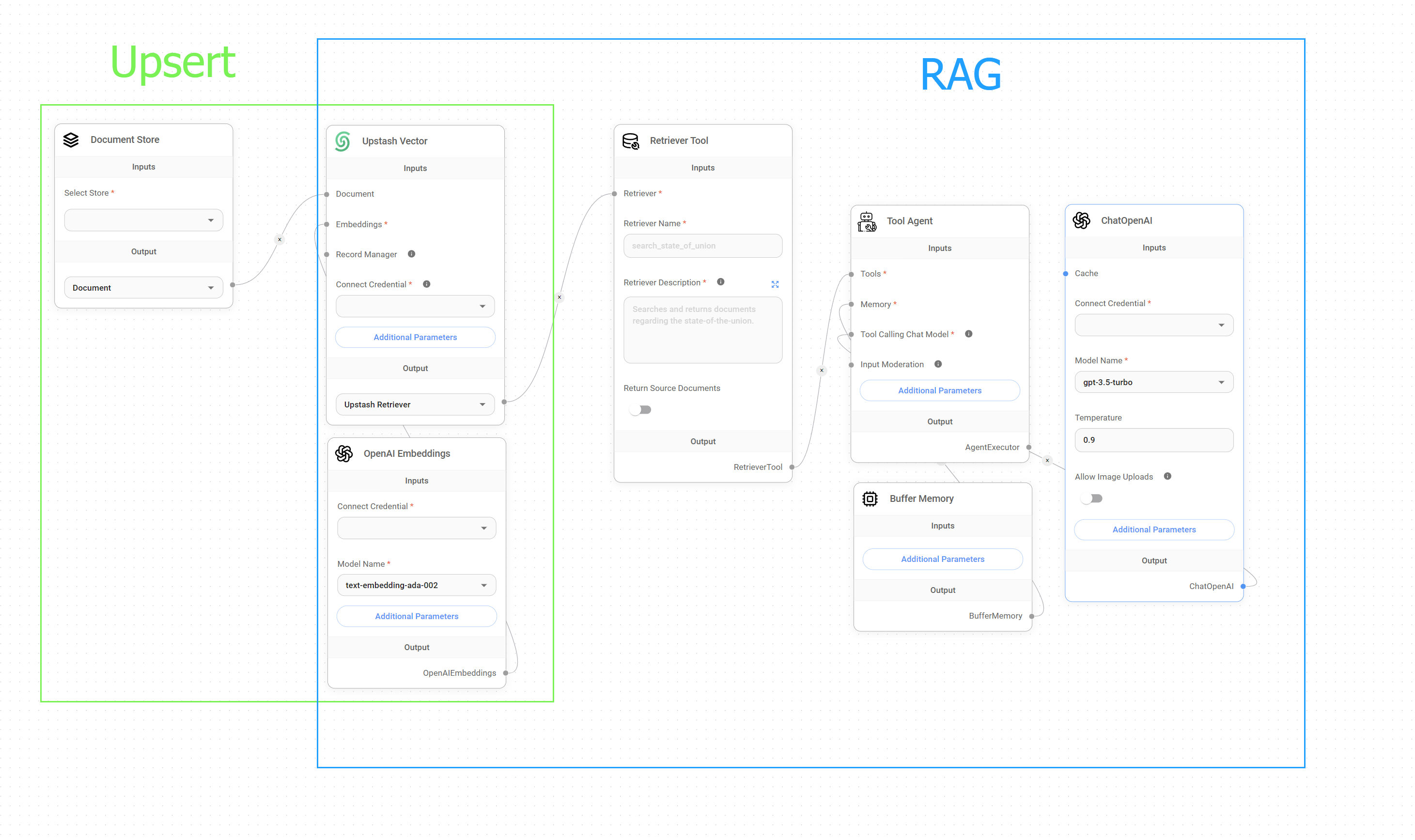
Upsert vs. RAG
Setup
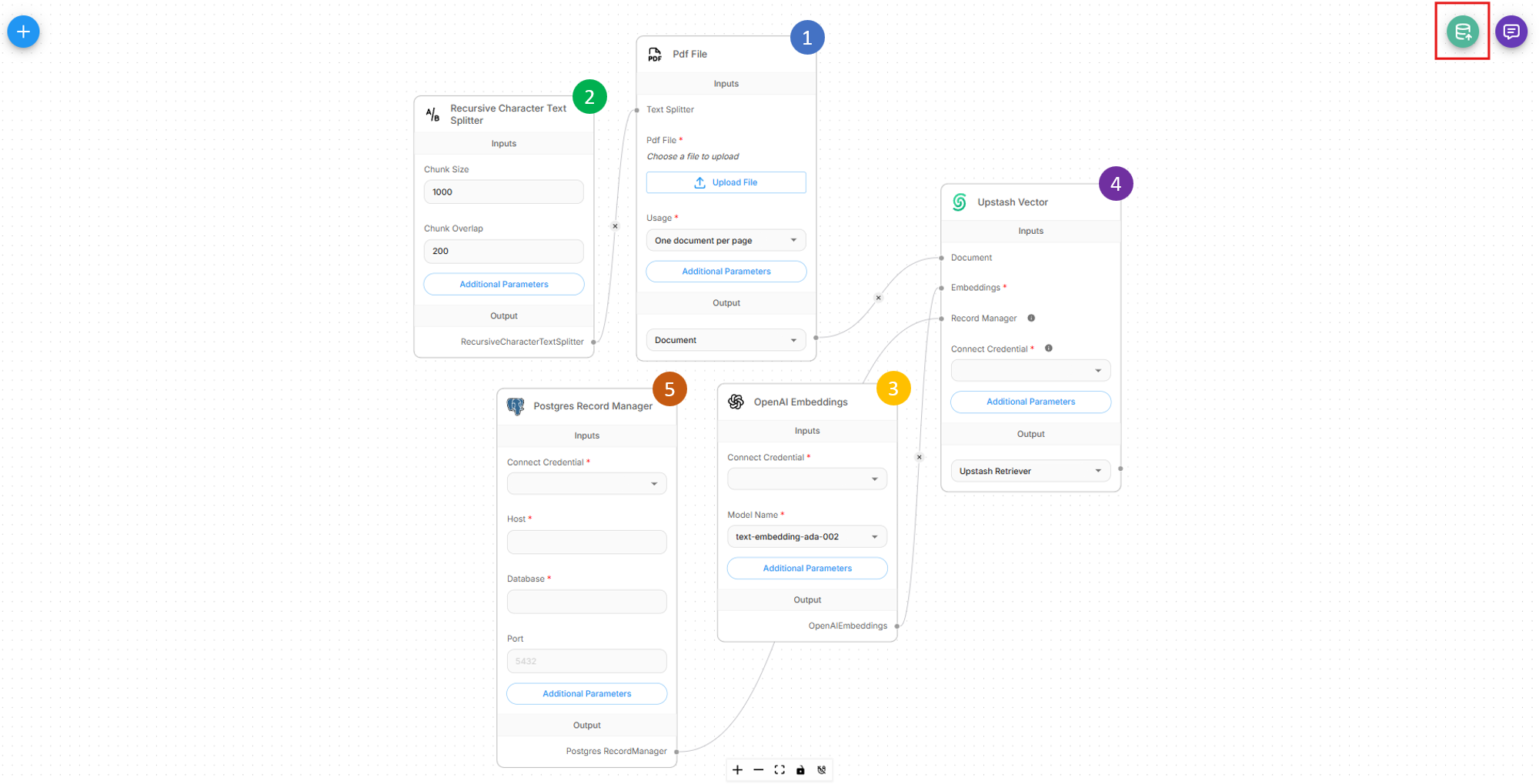
For an upsert process to work, we would need to create an upserting flow with 5 different nodes:
- Document Loader
- Text Splitter
- Embedding Model
- Vector Store
- Record Manager (Optional)
All of the elements have been covered in Document Stores, refer there for more details.
Once flow is setup correctly, there will be a green button at the top right that allows user to start the upsert process.
 (1) (1) (1) (1) (1).png)
The upsert process can also be carried out via API:
 (1) (1) (1) (1).png)
Base URL and Authentication
Base URL: http://localhost:3000 (or your Flowise instance URL)
Endpoint: POST /api/v1/vector/upsert/:id
Authentication: Refer Authentication for Flows
Request Methods
The API supports two different request methods depending on your chatflow configuration:
1. Form Data (File Upload)
Used when your chatflow contains Document Loaders with file upload capability.
2. JSON Body (No File Upload)
Used when your chatflow uses Document Loaders that don’t require file uploads (e.g., web scrapers, database connectors).
To override any node configurations such as files, metadata, etc., you must explicitly enable that option.
 (1) (1) (1).png)
Document Loaders with File Upload
Supported Document Types
| Document Loader | File Types |
|---|---|
| CSV File | .csv |
| Docx/Word File | .docx |
| JSON File | .json |
| JSON Lines File | .jsonl |
| PDF File | .pdf |
| Text File | .txt |
| Excel File | .xlsx |
| Powerpoint File | .pptx |
| File Loader | Multiple |
| Unstructured File | Multiple |
Important: Ensure the file type matches your Document Loader configuration. For maximum flexibility, consider using the File Loader which supports multiple file types.
Request Format (Form Data)
When uploading files, use multipart/form-data instead of JSON:
Examples
import requests
import os
def upsert_document(chatflow_id, file_path, config=None):
"""
Upsert a single document to a vector store.
Args:
chatflow_id (str): The chatflow ID configured for vector upserting
file_path (str): Path to the file to upload
return_source_docs (bool): Whether to return source documents in response
config (dict): Optional configuration overrides
Returns:
dict: API response containing upsert results
"""
url = f"http://localhost:3000/api/v1/vector/upsert/{chatflow_id}"
# Prepare file data
files = {
'files': (os.path.basename(file_path), open(file_path, 'rb'))
}
# Prepare form data
data = {}
# Add configuration overrides if provided
if config:
data['overrideConfig'] = str(config).replace("'", '"') # Convert to JSON string
try:
response = requests.post(url, files=files, data=data)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"Upload failed: {e}")
return None
finally:
# Always close the file
files['files'][1].close()
# Example usage
result = upsert_document(
chatflow_id="your-chatflow-id",
file_path="documents/knowledge_base.pdf",
config={
"chunkSize": 1000,
"chunkOverlap": 200
}
)
if result:
print(f"Successfully upserted {result.get('numAdded', 0)} chunks")
if result.get('sourceDocuments'):
print(f"Source documents: {len(result['sourceDocuments'])}")
else:
print("Upload failed")Document Loaders without File Upload
For Document Loaders that don’t require file uploads (e.g., web scrapers, database connectors, API integrations), use JSON format similar to the Prediction API.
Examples
import requests
from typing import Dict, Any, Optional
def upsert(chatflow_id: str, config: Optional[Dict[str, Any]] = None) -> Optional[Dict[str, Any]]:
"""
Trigger vector upserting for chatflows that don't require file uploads.
Args:
chatflow_id: The chatflow ID configured for vector upserting
config: Optional configuration overrides
Returns:
API response containing upsert results
"""
url = f"http://localhost:3000/api/v1/vector/upsert/{chatflow_id}"
payload = {
"overrideConfig": config
}
headers = {
"Content-Type": "application/json"
}
try:
response = requests.post(url, json=payload, headers=headers, timeout=300)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"Upsert failed: {e}")
return None
result = upsert(
chatflow_id="chatflow-id",
config={
"chunkSize": 800,
"chunkOverlap": 100,
}
)
if result:
print(f"Upsert completed: {result.get('numAdded', 0)} chunks added")Response Fields
| Field | Type | Description |
|---|---|---|
numAdded | number | Number of new chunks added to vector store |
numDeleted | number | Number of chunks deleted (if using Record Manager) |
numSkipped | number | Number of chunks skipped (if using Record Manager) |
numUpdated | number | Number of existing chunks updated (if using Record Manager) |
Optimization Strategies
1. Batch Processing Strategies
def intelligent_batch_processing(files: List[str], chatflow_id: str) -> Dict[str, Any]:
"""Process files in optimized batches based on size and type."""
# Group files by size and type
small_files = []
large_files = []
for file_path in files:
file_size = os.path.getsize(file_path)
if file_size > 5_000_000: # 5MB
large_files.append(file_path)
else:
small_files.append(file_path)
results = {'successful': [], 'failed': [], 'totalChunks': 0}
# Process large files individually
for file_path in large_files:
print(f"Processing large file: {file_path}")
# Individual processing with custom config
# ... implementation
# Process small files in batches
batch_size = 5
for i in range(0, len(small_files), batch_size):
batch = small_files[i:i + batch_size]
print(f"Processing batch of {len(batch)} small files")
# Batch processing
# ... implementation
return results2. Metadata Optimization
import requests
import os
from datetime import datetime
from typing import Dict, Any
def upsert_with_optimized_metadata(chatflow_id: str, file_path: str,
department: str = None, category: str = None) -> Dict[str, Any]:
"""
Upsert document with automatically optimized metadata.
"""
url = f"http://localhost:3000/api/v1/vector/upsert/{chatflow_id}"
# Generate optimized metadata
custom_metadata = {
'department': department or 'general',
'category': category or 'documentation',
'indexed_date': datetime.now().strftime('%Y-%m-%d'),
'version': '1.0'
}
optimized_metadata = optimize_metadata(file_path, custom_metadata)
# Prepare request
files = {'files': (os.path.basename(file_path), open(file_path, 'rb'))}
data = {
'overrideConfig': str({
'metadata': optimized_metadata
}).replace("'", '"')
}
try:
response = requests.post(url, files=files, data=data)
response.raise_for_status()
return response.json()
finally:
files['files'][1].close()
# Example usage with different document types
results = []
# Technical documentation
tech_result = upsert_with_optimized_metadata(
chatflow_id="tech-docs-chatflow",
file_path="docs/api_reference.pdf",
department="engineering",
category="technical_docs"
)
results.append(tech_result)
# HR policies
hr_result = upsert_with_optimized_metadata(
chatflow_id="hr-docs-chatflow",
file_path="policies/employee_handbook.pdf",
department="human_resources",
category="policies"
)
results.append(hr_result)
# Marketing materials
marketing_result = upsert_with_optimized_metadata(
chatflow_id="marketing-chatflow",
file_path="marketing/product_brochure.pdf",
department="marketing",
category="promotional"
)
results.append(marketing_result)
for i, result in enumerate(results):
print(f"Upload {i+1}: {result.get('numAdded', 0)} chunks added")Troubleshooting
- File Upload Fails
- Check file format compatibility
- Verify file size limits
- Processing Timeout
- Increase request timeout
- Break large files into smaller parts
- Optimize chunk size
- Vector Store Errors
- Check vector store connectivity
- Verify embedding model dimension compatibility